Эффективная методика поиска информации в сети Интернет
Артем ПОПОВ
popov@pol.ru
www.shipbottle.ru
На первых курсах института меня всегда удивляло умение преподавателя безошибочно находить ошибки в курсовой работе. Как бы вы ни пытались запутать решение и подогнать ответ, седому профессору достаточно было лишь заглянуть на первую и последнюю страницы проекта, и он возвращал работу нерадивому студенту. Только на старших курсах мы научились обходить препоны. Секрет оказался прост: нужно было подогнать не только ответ под условие, но и условие под ответ. Это знает любой старшекурсник. Попробуем употребить приобретенные в институте умения для поиска информации в сети Интернет. Подгоним запрос под результат. Для этого возьмем документ и, зная, как поисковая система собирается его обрабатывать, составим запрос. Вот тут-то и возникает маленькая загвоздка. Необходимо хотя бы в общих чертах знать, как система функционирует (наверное, именно на этом парадоксе построено все высшее образование). Ничего не поделаешь, придется разбираться с основами работы поисковой системы.
Автоматический анализ текстов
Оказывается, все созданные человеком тексты построены по единым правилам! Никому не удается обойти их. Какой бы язык ни использовался, кто бы ни писал — классик или графоман, — внутренняя структура текста останется неизменной. Она описывается законами Зипфа (G.K. Zipf). Зипф предположил, что природная лень человеческая (впрочем, это свойство любого живого существа) ведет к тому, что слова с большим количеством букв встречаются в тексте реже коротких слов. Основываясь на этом постулате, Зипф вывел два универсальных закона:
Первый закон Зипфа «ранг — частота»
Выберем любое слово и посчитаем, сколько раз оно встречается в тексте. Эта величина называется частота вхождения слова. Измерим частоту каждого слова текста. Некоторые слова будут иметь одинаковую частоту, то есть входить в текст равное количество раз. Сгруппируем их, взяв только одно значение из каждой группы. Расположим частоты по мере их убывания и пронумеруем. Порядковый номер частоты называется ранг частоты. Так, наиболее часто встречающиеся слова будут иметь ранг 1, следующие за ними — 2 и т.д. Ткнем наугад в стра
ницу и определим вероятность встретить слово, на которое пал выбор. Вероятность будет равна отношению частоты вхождения этого слова к общему числу слов в тексте.
Вероятность = Частота вхождения слова / Число слов
Зипф обнаружил интересную закономерность. Оказывается, если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина (С) приблизительно постоянна!
С = (Частота вхождения слова х Ранг частоты) / Число слов
Если мы немного преобразуем формулу, а потом заглянем в справочник по математике, то увидим, что это функция типа y=k/x и ее график — равносторонняя гипербола. Следовательно, по первому закону Зипфа, если самое распространенное слово встречается в тексте, например, 100 раз, то следующее по частоте слово вряд ли встретится 99 раз. Частота вхождения второго по популярности слова, с высокой долей вероятности, окажется на уровне 50. (Разумеется, вы должны понимать, что в статистике ничего абсолютно точного нет: 50, 52 — не так уж и важно.)
Значение константы в разных языках различно, но внутри одной языковой группы остается неизменно, какой бы текст мы ни взяли. Так, например, для английских текстов константа Зипфа равна приблизительно 0,1. Интересно, как выглядят с точки зрения законов Зипфа русские тексты? Они не исключение. Анализ хранящихся в моем компьютере файлов с русскими текстами убедил, что закон безупречен и тут. Для русского языка коэффициент Зипфа получился равным 0,06-0,07. Хотя эти исследования не претендуют на полноту, универсальность законов Зипфа позволяет предположить, что полученные данные вполне достоверны.
Второй закон Зипфа «количество — частота»
Рассматривая первый закон, мы отмахнулись от факта, что разные слова входят в текст с одинаковой частотой. Зипф установил, что частота и количество слов, входящих в текст с этой частотой, тоже связаны между собой. Если построить график, отложив по одной оси (оси Х) частоту вхождения слова, а по другой (оси Y) — количество слов в данной частоте, то получившаяся кривая будет сохранять свои параметры для всех без исключения созданных человеком текстов! Как и в предыдущем случае, это утверждение верно в пределах одного языка. Однако и межъязыковые различия невелики. На каком бы языке текст ни был написан, форма кривой Зипфа останется неизменной. Могут немного отличаться лишь коэффициенты, отвечающие за наклон кривой [рис. 1]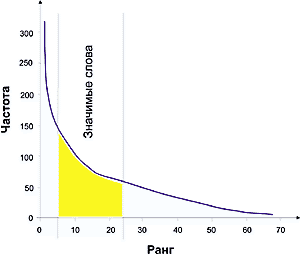 (в логарифмическом масштабе, за исключением нескольких начальных точек, график — прямая линия).
(в логарифмическом масштабе, за исключением нескольких начальных точек, график — прямая линия).
Законы Зипфа универсальны. В принципе, они применимы не только к текстам. В аналогичную форму выливается, например, зависимость количества городов от числа проживающих в них жителей. Характеристики популярности узлов в сети Интернет — тоже отвечают законам Зипфа. Не исключено, что в законах отражается «человеческое» происхождение объекта. Так, например, ученые давно бьются над расшифровкой манускриптов Войнича. Никто не знает, на каком языке написаны тексты и тексты ли это вообще. Однако исследование манускриптов на соответствие законам Зипфа доказало: это созданные человеком тексты. Графики для манускриптов Войнича точно повторили графики для текстов на известных языках.
Что дают нам законы Зипфа? Как с их помощью извлечь слова, отражающие смысл текста? Воспользуемся первым законом Зипфа и построим график зависимости ранга от частоты. Как уже упоминалось, его форма всегда одинакова [рис. 2]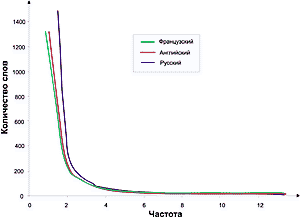 .
.
Исследования показывают, что наиболее значимые слова лежат в средней части диаграммы. Это и понятно. Слова, которые попадаются слишком часто, в основном оказываются предлогами, местоимениями, в английском — артиклями и т.п. Редко встречающиеся слова тоже, в большинстве случаев, не имеют решающего смыслового значения.
От того, как будет выставлен диапазон значимых с
лов, зависит многое. Поставь широко — нужные термины потонут в море вспомогательных слов; установи узкий диапазон — потеряешь смысловые термины. Каждая поисковая система решает проблему
по-своему, руководствуясь общим объемом текста, специальными словарями и т.п. Проведем эксперимент. Подвергнем абзац текста математическому анализу и попытаемся определить список значимых слов.
В качестве примера возьмем один из предыдущих абзацев (абзац, начинающийся словами «Законы Зипфа универсальны»). Посмотрим, какие слова попали в область значимых слов, а какие нет. В таблице 1 приведены все слова абзаца и указана частота их вхождения. Как видите, слова с частотой 2 и 3 наиболее точно отражают смысл абзаца. Слово с наибольшей частотой вхождения оказалось предлогом, а слова с меньшей — общими словами.
На рисунке 3 приведен график частота-ранг этого абзаца. Выделим зону значимых слов. Пусть это будут слова с рангом 2, 3 и частотой 3, 2 соответственно. (Обратите внимание, как смещение или расширение зоны значимых слов влияет на их состав.)
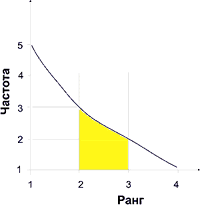
Давайте теперь проанализируем выделенную нами область значимых слов. Не все слова, которые попали в нее, отражают смысл текста. Смысл абзаца очень точно выражают слова: зипфа, манускриптов, войнича, законам. Запрос типа: + «закон* зипфа» + «манускрипт* войнича» непременно найдет нам этот документ. Однако в область попали и слова: на, не, для, например, это. Эти слова являются «шумом», помехой, которая затрудняет правильный выбор. «Шум» можно уменьшить путем предварительного исключения из исследуемого текста некоторых слов. Для этого создается словарь ненужных слов — стоп-слов (словарь называется стоп-лист). Например, для английского текста стоп-словами станут термины: the, a, an, in, to, of, and, that… и так далее. Для русского текста в стоп-лист могли бы быть включены все предлоги, частицы, личные местоимения и т. п. Наверняка попали бы и слова из нашего «шума»: на, не, для, это. Есть и другие способы повысить точность оценки значимости терминов.
Весовые коэффициенты
До сих пор мы рассматривали отдельно взятый документ, не принимая во внимание, что он входит в базу данных наряду с множеством других документов. Если представить всю базу данных как единый документ, к ней можно будет применить те же законы, что и к единичному документу. Посмотрите на список терминов в нашем примере. В одну компанию попали слова-термины зипфа и не — они входят в документ равное количество раз. Исследовав остальные документы базы данных на предмет вхождения в них этих терминов, мы, естественно, обнаружим, что не встречается очень часто, в то время как зипфа — довольно редко. Напрашивается очевидный вывод: слово зипфа должно стать термином, в то время как не следует отбросить, как помеху. Чтобы избавиться от лишних слов и в тоже время поднять рейтинг значимых слов, вводят инверсную частоту термина. Значение этого параметра тем меньше, чем чаще слово встречается в документах базы данных. Вычисляют его по формуле:
Инверсная частота термина i = log (количество документов в базе данных / количество документов с термином i).
Теперь каждому термину можно присвоить весовой коэффициент, отражающий его значимость:
Вес термина i в документе j = частота термина i в документе j х инверсная частота термина i.
Наверняка в нашем примере термин не получит нулевой или близкий к нулю вес, поскольку практически во всех текстах попадается это слово. Термин же зипфа — напротив, приобретет высокий вес.
Современные способы индексирования не ограничиваются анализом перечисленных параметров текста. Поисковая машина может строить весовые коэффициенты с учетом местоположения термина внутри документа, взаимного расположения терминов, частей речи, морфологических особенностей и т.п.
В качестве терминов могут выступать не только отдельные слова, но и словосочетания. Джорж Зипф (George K. Zipf) опубликовал свои законы в 1949 году. Пять лет спустя знаменитый математик Беноит Мандлеброт (Benoit Mandlebrot) внес небольшие изменения в формулы Зипфа, добившись более точного соответствия теории практике. Без этих законов сегодня не обходится ни одна система автоматического поиска информации. Как видите, математический анализ позволяет машине с хорошей точностью, без участия человека распознать суть текста.
Представление базы данных
Итак, мы разобрались, как машина «понимает» суть текста. Теперь необходимо организовать всю коллекцию документов так, чтобы можно было легко отыскать в ней нужный материал. База данных должна взаимодействовать с пользовательским запросом. Запросы могут быть простыми, состоящими из одного слова, и сложными — из нескольких слов, связанных логическими операторами. Простой запрос оправдывает свое название. Пользователь вводит слово, машина ищет его в списке терминов и выдает все связанные с термином ссылки. Структура такой базы данных проста. Взаимодействие со сложными запросами требует более изощренной организации.
Матричное представление базы данных
| Д1 | Д2 | Д3 | Д4 | Д5 | Д6 | Д7 | Д8 | |
| Алкоголизм | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| Бутылка | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| Вино | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| Корабль | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Модель | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| Море | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| Парус | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| Пиво | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| Судо- моделизм |
0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| Урожай | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 |
| Хобби | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
Наиболее простой способ представить элементы базы данных в форме, удобной для многовариантного поиска — создать матрицу документ-термин.
Предположим, база данных имеет 8 документов (Д1, Д2, Е, Д8), в которых содержатся 12 терминов. Если термин входит в документ, в соответствующей клеточке ставится единица, в противном случае — ноль (в реальной системе все сложнее: помимо прочего, учитываются еще и весовые коэффициенты терминов).
Составим, например, такой запрос: корабл
и в бутылках. Система обработает запрос: удалит стоп-слова и, возможно, проведет морфологический анализ. Останется два термина: корабль и бутылка. Система будет искать все документы, где встречается хотя бы один из терминов. Посмотрим на матрицу. Указанные в запросе термины есть в документах: Д1, Д2, Д4, Д7, Д8. Они и будут выданы в ответ на запрос. Однако нетрудно заметить, что документы Д4 и Д7 не удовлетворяют нашим чаяниям — они из области виноделия и никакого отношения к постройке моделей кораблей в бутылках не имеют. Впрочем, система все сделала правильно, ведь, с ее точки зрения, термины корабль и бутылка равноценны.
Пространственно-векторное представление базы данных
Пространственно-векторная модель позволяет получить результат, хорошо согласующийся с запросом. Причем документ может оказаться полезным, даже не имея 100% соответствия. В найденном документе может вовсе не оказаться одного или нескольких слов запроса, но при этом его смысл будет запросу соответствовать. Как достигается такой результат?
Все документы базы данных размещаются в воображаемом пространстве (это может быть многомерное пространство, представить которое весьма трудно). Координаты каждого документа зависят от структуры терминов, в нем содержащихся (от весовых коэффициентов, положения внутри документа, от расстояния между терминами и т.п). В результате окажется, что документы с похожим набором терминов разместятся в пространстве ближе друг к другу [рис. 4].
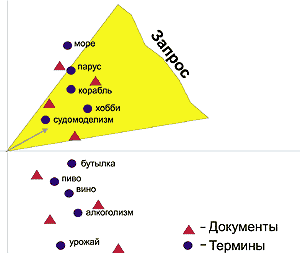
Предположим, мы хотим найти документы, касающиеся постройки моделей кораблей в бутылках. Составим запрос, например, такой: корабли в бутылках. Получив его, поисковая система удалит лишние слова, выделит термины и вычислит вектор запроса в пространстве документов (стрелочка на рисунке). Установив некоторый диапазон соответствия, система выдаст документы, попавшие в заштрихованную область на рисунке 4.
Эта область непременно захватит документы, повествующие о необычных увлечениях — хобби, классическом судомоделизме и т.п. В них может вовсе не оказаться некоторых слов запроса, однако документы останутся достаточно релевантными. Термины, относящиеся к вину, будут группироваться в другой точке пространства, и запрос их не затронет. Как видите, «уравниловку» терминов удалось преодолеть. В пространственно-векторной модели термины взаимодействуют друг с другом, что повышает релевантность документов. Понятно, что пространственно-векторная модель лучше воспринимает запросы, составленные на естественном языке, чем матричная.
К сожалению, догадаться, по какой схеме работает та или иная поисковая система Интернета, очень трудно. Как правило, создатели держат ее в секрете. Мы в простой форме изложили лишь основы работы поисковой системы. В реальности механизм индексации и структура базы данных значительно сложнее. Однако полученных знаний уже достаточно, чтобы попытаться выработать оптимальную стратегию поиска информации в сети Интернет.
Стратегия поиска
Итак, мы знаем, как система выделяет ключевые слова. Воспользуемся этим знанием, чтобы сформировать оптимальный запрос. Прежде всего оговорим некоторые исходные предпосылки. Допустим, мы имеем некий текст-источник и хотим найти в сети Интернет документы схожего содержания. Откуда возьмется текст-источник? Поскольку сама задача поиска не могла возникнуть из ничего, где-то непременно должна существовать информация, возбудившая интерес к проблеме. Может быть, это журнальная статья, книга, веб-страница и т.п. Именно эту информацию и нужно упорядочить и привести в форму, удобную для анализа. Если задача существует только у вас в голове, попробуйте написать небольшое сочинение, изложив свое видение проблемы, — оно и станет текстом-источником. Если бы нам удалось препарировать текст-источник так же, как это делает поисковая машина, по идее, мы могли бы получить результаты с максимально высокой релевантностью. Попробуем. Возьмем текст-источник и проанализируем его. Для автоматизации процесса можно заглянуть на интерактивную страничку www.shipbottle.ru/ir/, где функционирует с грехом пополам сооруженный автором апплет, или воспользоваться небольшой программкой MTAS (mtasprog.exe) (www.sas.upenn.edu/~bkat/dwnld.htm). (Внимательно прочтите инструкцию: для обработки русского текста придется написать небольшой файл-алфавит.) Если текст-источник — файл на диске вашего компьютера, укажите программе путь к нему — она сама вычислит все необходимые параметры. В противном случае, например, когда текст-источник — страница в журнале, анализ придется сделать вручную.
Последовательность действий такова:
- Подбираем текст-источник. Чем четче описание проблемы в тексте-источнике, тем качественнее и точнее окажется результат. Размытый и путаный текст-источник выудит из поисковой системы столь же бестолковые документы.
- Удаляем из текста стоп-слова (их можно просто вычеркивать).
- Вычисляем частоту вхождения каждого термина. Причем делаем это без учета морфологии слов. Так, слова ship и ships будут разными терминами. Не нужно учитывать и регистр, все буквы считаем строчными.
- Выписываем на отдельный лист термины в порядке убывания их частоты вхождения (первыми должны идти те, которые встречаются чаще).
- Выбираем диапазон частот. Он должен лежать где-нибудь посередине. Не нужно брать слишком часто или, наоборот, слишком редко встречающиеся термины. Выбор диапазона субъективен. Вам следует ориентироваться на конкретный смысл текста. Необходимость выбирать диапазон вручную не должна смущать, ведь теперь вы выбираете термины не из текста, а из построенного по определенному закону упорядоченного списка.
- Из выбранного диапазона выписываем термины. В большом тексте в диапазоне может оказаться довольно много слов. Все их применить вряд ли удастся. Достаточно взять 10-20 терминов. Их следует выбирать, руководствуясь, в первую очередь, здравым смыслом. Причем не стоит ограничиваться только характерными терминами, даже если они кажутся наиболее удачными. В список должны попасть и общие слова (их лучше выбирать из средней части диапазона).
- Составляем запрос, располагая отобранные слова в порядке их следования в списке терминов. Запрос должен пониматься машиной как слова, связанные логическим оператором ИЛИ. Это очень важное требование. Чтобы результат не исказился, следует изучить особенности синтаксиса запросов конкретной поисковой системы.
- Отправляем запрос поисковой системе.
В ответ вы можете получить несколько миллионов ссылок. Но не пугайтесь. Если поисковая машина ранжирует результаты (а это еще одно необходимое условие), на первых страницах окажутся практически стопроцентно релевантные документы. Самое любопытное, что документ — источник запроса (если его аналог существует в Интернете) вовсе не обязательно будет возглавлять список. Он может оказаться и на задворках.
Проверка метода на практике
Разумеется, предлагаемый метод поиска нельзя назвать универсальным. Далеко не все поисковые машины воспримут его с одинаковым восторгом. Какими же свойствами должна обладать поисковая система, чтобы применение метода было оправдано? Множество факторов оказывают влияние на результат. Это и общий объем базы данных, и механизм индексации, структура данных и так далее, и тому подобное. Но наиболее важными, на мой взгляд, являются два умения поисковой системы: способность понимать запросы, составленные на разных языках (для нас — на русском), и мощное ранжирование результатов. С русским языком все понятно — без него нам в Интернете не интересно. Но почему так важно ранжирование? Мы договорились вводить запрос с логикой ИЛИ. Это сильно увеличивает количество возвращаемых поисковой машиной документов. Без ранжирования всякий поиск теряет смысл. Наилучшие результаты дает ранжирование по схеме:
точное соответствие — все слова запроса — все слова, кроме последнего, — все слова, кроме двух последних, — … — все слова, кроме n последних, — первое слово (плюс, разумеется, ранжирование по количеству терминов в тексте). Алгоритм может быть и более мощным, но даже при такой последовательности мы можем быть уверены, что, сколько бы документов найдено ни было, наиболее удачные окажутся впереди.
Наилучшие результаты в поиске по предлагаемому методу продемонстрировала система AltaVista (www.altavista.digital.com). (Это неудивительно, ведь метод разрабатывался с оглядкой именно на нее.) Хотя на тестовый запрос система выдала более 5 миллионов ссылок, для англоязычного запроса на первых трех страницах все ссылки оказались абсолютно релевантными! (Причем документ-источник появился только на третьей странице.) Для русского текста из десяти ссылок на первой странице точными оказались только первые восемь. Однако при ближайшем изучении выяснилось, что это все, что есть в Интернете на искомую тему.
Что происходило на других поисковых системах? Картина сложилась пестрая. Одни справились не хуже лидера, другие не справились вовсе. Прежде чем «перемывать косточки», хочу, чтобы вы поняли: неудача говорит не о несовершенстве той или иной поисковой системы или метода, а лишь о неприменимости выбранного метода поиска для данной поисковой машины.
Начнем с зарубежных поисковых систем. Помимо AltaVista очень хороший результат в поиске на английском языке показал HotBoot (www.hotbot.com) . Увы, запрос на русском языке поставил его в тупик. Очевидно, русские буквы для сервера HotBoot — непреодолимое препятствие. Оценить Yahoo! мне не удалось из-за характерной формы вывода результатов. На тестовый запрос был получен объемистый список каталогов, копаться в которых показалось бессмысленным. Более скромные поисковые машины Northern Light, Excite, Infoseek и другие хотя и выполнили задание, но обилием релевантных ссылок не поразили (возможно, просто из-за того, что их базы данных не столь велики). Для поиска на английском языке на первых страницах оказалось 40-60% релевантных ссылок (впрочем, не такой уж плохой результат). При обработке запроса на русском языке эти системы проявили любопытное единодушие. Было найдено множество документов, но, как мне показалось, никакого ранжирования не было проведено вовсе. В итоге на первую страницу могло попасть, случайно, от силы один-два релевантных документа.
Самостоятельное применение пользователем для решения той или иной задачи любого осмысленного метода требует от системы отсутствия в ней излишней опеки. Автомобиль с автоматической коробкой передач, которая все делает за вас, вещь хорошая, но вряд ли целесообразно отправляться на нем в ралли Париж — Дакар. То же и в поисковой системе. Чрезмерное увлечение морфологической обработкой слов может лишить поиск гибкости. На мой взгляд, именно этим грешат некоторые российские поисковые системы. Спору нет, удобно ввести в поле запроса фразу на естественном языке и получить список документов, которые (по мнению поисковой машины) этому запросу удовлетворяют. Такой поиск дает неплохой результат в среднем. Однако любое отклонение в сторону от утвержденной схемы может резко снизить эффективность поиска. Все эти соображения первоначально вызывали серьезные сомнения в применимости метода на отечественных поисковых серверах. Что же получилось в реальности?
В целом опасения подтвердились. Для системы «Апорт!» выбранная методика оказалась полностью чужда. Rambler представил хорошие результаты только после того, как логика запроса была изменена на И. На первой странице все документы, как для русского, так и английского поиска, оказались полностью релевантными. Увы, логика И неизбежно ведет к потере весомой части релевантных документов. С поиском на английском языке отлично справился Яndex (yandex.ru) — стопроцентная релевантность на первой странице для англоязычного запроса. Однако русский запрос был обработан заметно слабее. Изучение отклика российских поисковых систем привело к парадоксальному (и крамольному) выводу: морфологическая обработка не обязательно увеличивает число релевантных документов! Разумеется, это утверждение не бесспорно. Для других методик поиска морфологический анализ может оказаться незаменимым; в предлагаемой же нами — он явно лишний. Недаром так хорошо справилась с задачей AltaVista — в ней даже английский текст морфологически не обрабатывается. Все слова для нее, за редким исключением (имеется в виду стоп-лист, но он создается только для англоязычных и близких к ним текстов), лишь последовательность символов.
Предлагаемая методика поиска информации в сети Интернет хорошо подходит для исчерпывающего обзорного поиска. Обзорный поиск незаменим, когда нужно найти как можно больше документов на заданную тему. Анализ текста-источника вручную — весьма трудоемкое и скучное занятие. Чтобы облегчить его, по адресу www.shipbottle.ru/ir/ вы найдете апплет, реализующий метод. Не все еще в нем работает идеально, за что заранее приношу извинения. Со временем я постараюсь расширить возможности апплета и сделать его более функциональным.
Если вы нашли ошибку, выделите ее и нажмите Shift + Enter или нажмите здесь чтобы сообщить нам.
